
Peilin Cai’s Personal Website
About
I am a master student researcher focused on computer vision (CV), large language models (LLMs), and multimodal generation. At USC’s Graphics & Vision Lab (advisor: Prof. Yue Wang), my work centers on 3D reconstruction under sparse observations, controllable generative rendering, and embodied navigation.
More broadly, my research is driven by a simple goal: to enable models that both perceive and generate the real world in a scalable, physically grounded way. From structured 3D reconstruction during my undergraduate years at Wuhan University to my current work on large language models, world models, and embodied agents at USC, a recurring theme has been bridging raw sensory data with structured representations of scenes, actions, and goals. Looking ahead to a PhD, I hope to develop unified models of perception and generation for lifelong scene understanding and robust, context-aware agents.
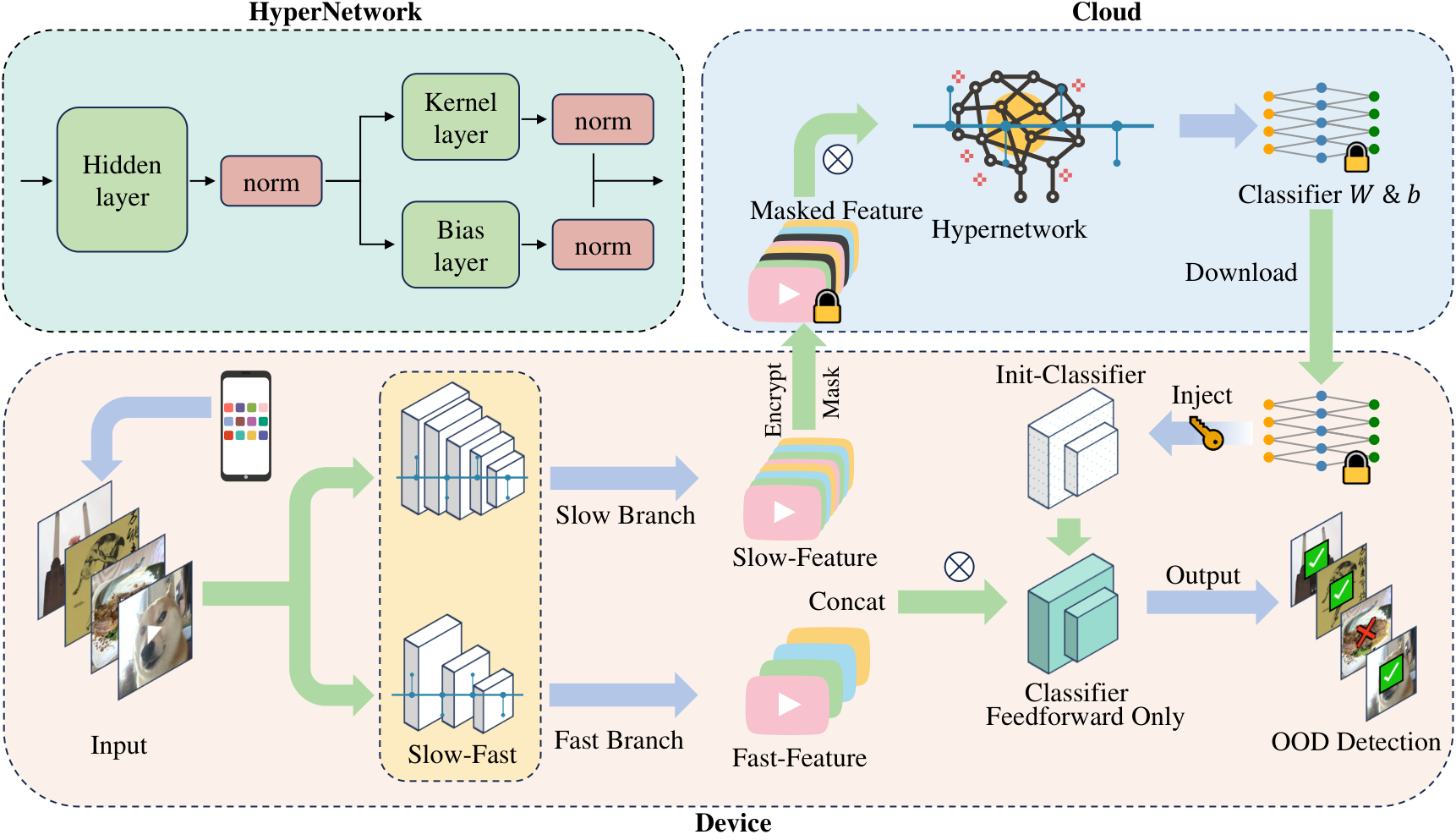
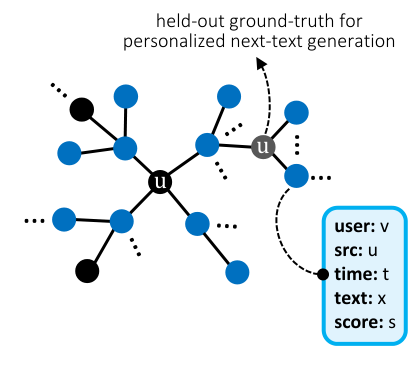
I carried out two research projects of great personal significance at Prof. Yue Zhao’s FORTIS Lab: SecDOOD (ICCV 2025 Poster) and PERSONABENCH (NeurIPS 2025 MTI-LLM Spotlight). The former proposed a secure on-device OOD detection framework that requires no gradient backpropagation, offering insights for deploying personalized large models on edge devices; the latter introduced the first benchmark for evaluating the personalization capabilities of LLMs in multi-turn conversational settings. I am deeply grateful to Prof. Yue Zhao and the senior PhD students in the lab for their support.
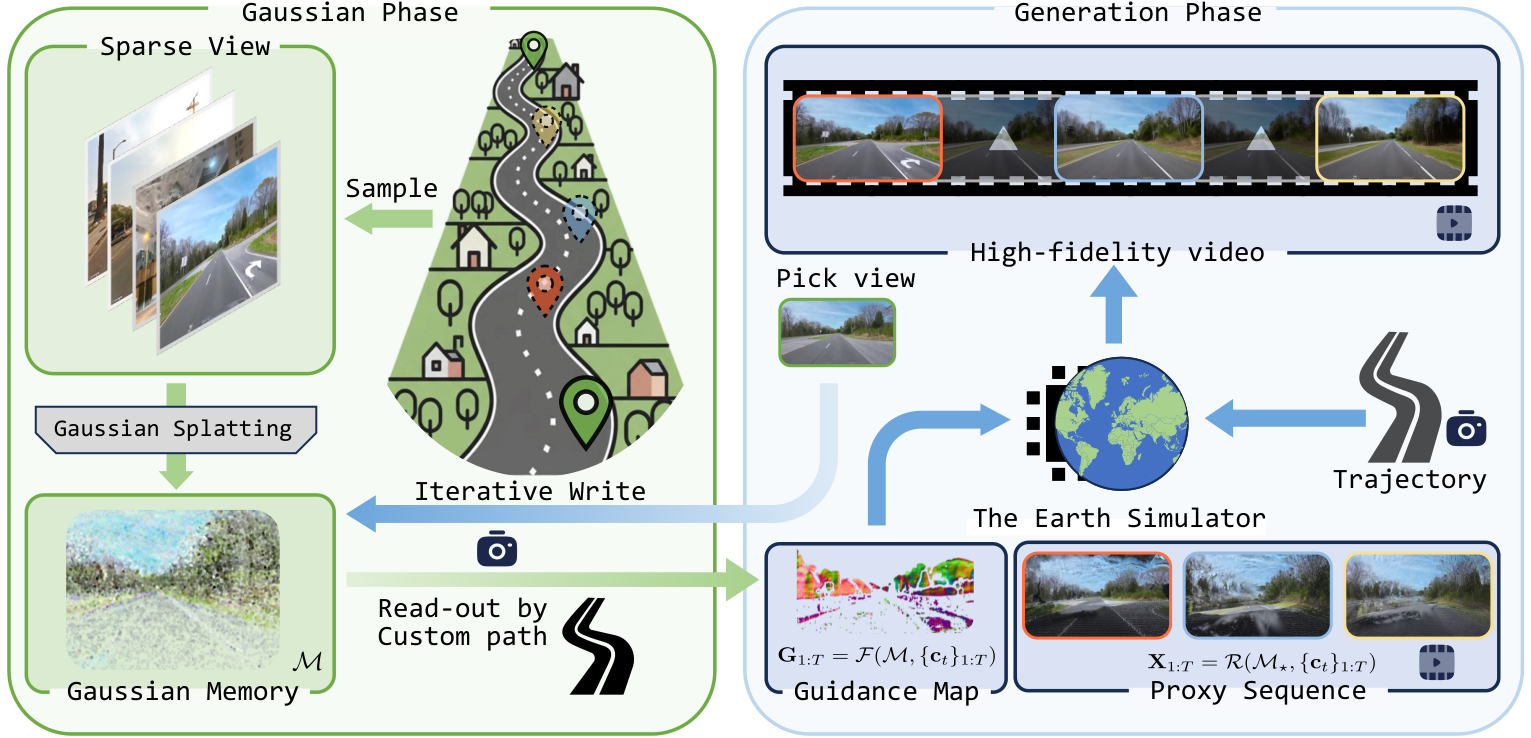
At GVL, I developed The Earth Simulator, a street-view world model that turns a handful of raw, pose-free images into long-horizon, camera-controllable exploration videos grounded in 3D geometry. By combining a persistent 3D Gaussian spatial memory with a generative video model, we aim to preserve real-world structure while achieving photorealistic, temporally stable rollouts from sparse, in-the-wild driving footage rather than costly calibrated data collection. Source code and preprints are on the way!
I have strong coding skills and a solid background in computer vision and natural language processing, as well as extensive experience in training, deploying, and running inference with LLMs / VLMs. And I am also honing my research skills in robotics at the GVL Lab. If you are interested in collaborating, please feel free to reach out. My preferred email is peilinca@usc.edu
Current State:
- In my third semester of the M.S. in Computer Science program at the University of Southern California.
- Currently working on two projects that will be submitted for publication.
- Seeking PhD opportunities.
Publications
-
 In Submission
In Submission - The Earth Simulator: Street View World Modeling with 3D Gaussian Memory and Camera Control
- in Submission, 2025
-
 ICCV 2025 Poster
ICCV 2025 Poster - Secure On-Device Video OOD Detection Without Backpropagation
- in International Conference on Computer Vision, 2025
-
 NeurIPS 2025 MTI-LLM Workshop Spotlight (Top 5%)
NeurIPS 2025 MTI-LLM Workshop Spotlight (Top 5%) - A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
- in arxiv preprint, 2025